컴퓨터 네트워크란?
컴퓨터와 컴퓨터를 통신망으로 연결한 것
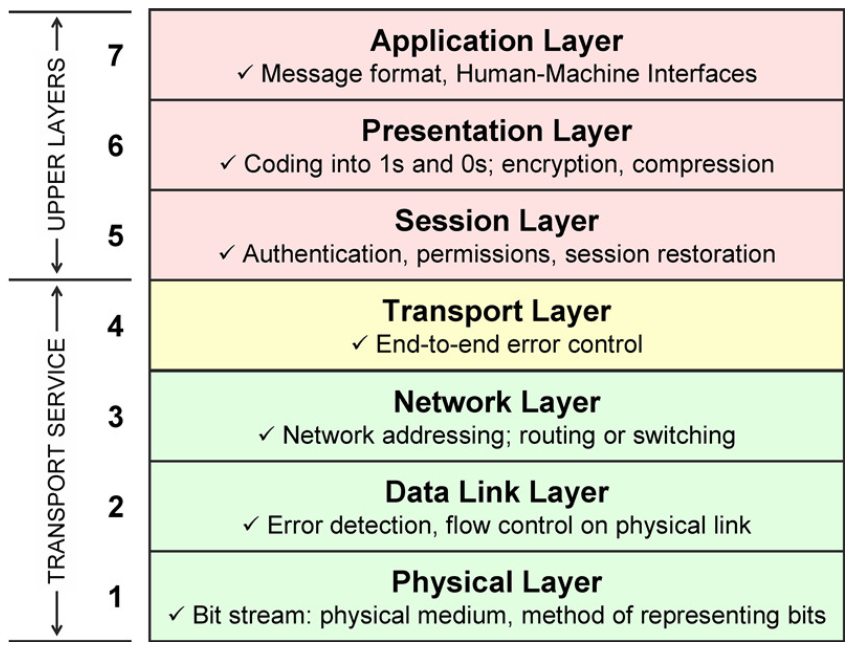
컴퓨터 네트워크를 배울 때는 OSI모형(Open Systems Interconnection Reference Model)을 기반으로 공부한다.
OSI 7계층으로 알고 있는데, 각 계층은 하위 계층의 서비스를 받으면서 상위 계층에게 서비스를 제공한다.
먼저 OSI 1계층(물리) 부터 4계층(전송) 계층까지 살펴본 뒤, 리눅스 환경에서 5 세션 계층~ 7 응용 계층 까지 알아보자.
목표
컴퓨터 네트워크의 목표는 간단하다. 컴퓨터로부터 다른 컴퓨터로 데이터를 전송하는 것, 목표는 간단하지만 실제로는 매우 복잡한 과정을 거친다. 전송 계층에서 신뢰성 있는 전송 서비스를 제공하는 것, 네트워크 계층에서 네트워크 노드 간의 라우팅 서비스를 제공하는 것, 데이터 링크 계층에서 물리적으로 연결된 노드에게 데이터를 전송하는 서비스를 제공하는 것, 물리 계층에서 실제로 신호를 비트로 전송하는 서비스를 제공하는 것이 잘 이루어져야 비로소 Host에게 데이터가 전송된다. 이 글에서는 물리 계층과 데이터 링크 계층은 간략하게 언급하고, 네트워크 계층, 전송 계층 그리고 그 상위 계층에 대해서 자세하게 알아보자.
먼저 별도의 용어를 정리해보자.
- 컴퓨터 네트워크(Computer Network) : 컴퓨터와 컴퓨터를 통신망으로 연결한 것
- 노드(Node) : 컴퓨터 네트워크상에 연결된 장치
- 호스트(Host) : 고유 IP 주소를 가진 노드
- 링크(Link) : 물리적으로 노드와 노드를 연결하는 통로
- 홉(Hop) : 거리의 단위, 보통 한 링크를 이동하면 한 홉이라고 한다.
- 경로(Path) : 네트워크 상의 두 노드 간의 이동 경로
- 프로토콜(Protocol) 데이터 통신을 원활하게 하기 위해 필요한 통신 규약
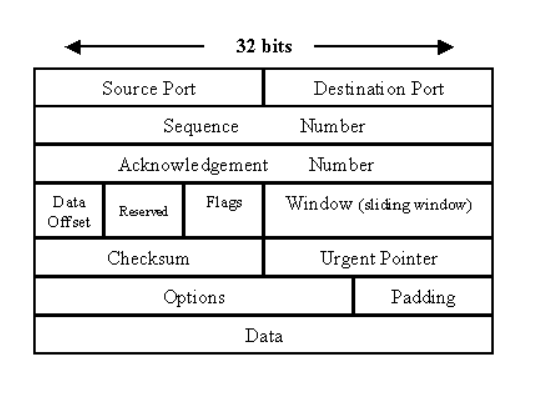
전송 계층에서 제공하는 서비스는 신뢰성 있는 통신인 TCP(Transmission Control Protocol)와 신뢰성 없는 통신인 UDP(User Datagram Protocol)로 나뉜다. 응용 프로그램이 소켓을 통해 보내는 데 데이터 단위는 메시지(Message, TCP 통신에서 데이터 단위는 세그먼트(Segment), UDP 통신에서 데이터 단위는 데이터그램(Datagram)이라고 한다. 네트워크 계층에서는 패킷(Packet)이라는 데이터 단위를 사용하고, 데이터 링크 계층에서는 프레임(Frame), 마지막으로 물리 계층에서는 비트(Bit) 단위로 전송한다. 이 단위는 프로토콜 데이터 단위(Protocol Data Unit)로 알려진 것인데, OSI 모델에서 단위이다. 인터넷 프로토콜 수트(Inter Protocol Suite) 에서는 전송 계층에서의 단위를 세그먼트, 네트워크 계층에서의 단위를 데이터그램, 네트워크 접근 계층에서의 단위를 프레임으로 부른다.
각 계층에서는 하위 계층으로 문제없이 서비스를 잘 받고, 실제로 어떻게 작동하는지 알 필요가 없다는 가정 하에 진행된다. 실제로 어떻게 작동하는지는 알 필요가 없다는 가정 하에 진행된다. 예를 들어 전송 계층에서는 목적지까지 데이터를 잘 전송하는 서비스를 제공하는 것이 목표인데, 하위 계층의 역할인 패킷 경로 제어에 대해서는 관심을 두지 않는다. 이러한 원칙은 투명성(Transparent)으로 널리 알려져 있다. (안보이게 하는 것)
연결 지향(Connection Oriented) 프로토콜과 비연결(Connectionless) 프로토콜
통신 연결이 유지되는 것을 지향하는 프로토콜을 연결 지향 프로토콜, 연결을 유지하지 않는 프로토콜을 비연결 프로토콜이라고 한다. 연결 지향 프로토콜은 연결을 계속 유지하기 위한 비용이 들기 때문에 더 비싼 반면 비연결 프로토콜은 연결 유지 비용이 들지 않기 때문에 저렴하다. 예를 들어 전화 연결은 연결된 상태를 유지하기 때문에 연결 지향 프로토콜이라고 볼 수 있다. 비싸다고 무조건 나쁜 것이 아니고, 싸다고 무조건 좋은 것이 아니기 때문에 적절한 선택을 해야한다.
IIP 프로토콜은 비연결 프로토콜이지만 IP 프로토콜을 이용하는 TCP프로토콜은 연결 지향 프로토콜이다. 또 다시 TCP 프로토콜을 이용하는 HTTP 프로토콜은 비연결 프로토콜이다. 이렇든 프로토콜을 어떻게 활용하느냐에 따라 연결지향과 비연결 프로토콜로 바뀔 수 있다.
연결 지향 프로토콜에서는 이미 연결되어 있기 떄문에 어떤 사람이 질의를 보냈는지 연결을 이용하여 알 수 있다. 위에서 예를 든 전화 통화는 이미 통화 연결이 성립될 때 서로 누군지 알기 때문에 연결이 유지되어 있기만 하면 시간이 지난 뒤 다시 말을 해도 누군지 알 수 있다. 하지만 비연결 프토로콜은 매번 새롭게 연결이 성립되기 떄문에 필요한 경우 매 연결 시 자신이 누구인지 알려줘야 한다. 예를 들어 HTTP 프로토콜을 이용한 웹 환경의 경우 쿠키나 세션을 통해 매 번 자신을 식별할 수 있는 정보를 함께 전송한다.
전송 계층(Transport Layer)
전송 계층의 역할은 목적지까지 데이터를 잘 도착하도록 하는 것이다. 연결 지향 데이터 스트림 지원, 신뢰성 있는 데이터 전송, 흐름 제어, 그리고 다중화와 같은 편리한 서비스를 제공한다. 전송 계층에서 가장 널리 알려진 프로토콜이 바로 TCP, UDP 프로토콜이다. 앞서 나열한 편리한 서비스들은 거의 다 TCP 프로토콜로 제공되는 것이다. 이러한 편리한 서비스들을 제공하기 위해서는 복잡한 처리를 요구하고, 이는 TCP 프로토콜을 이용하는 비용이 크다는 것을 뜻한다. 때로는 이러한 서비스들이 필요 없는 경우도 있다. 그런 때에는 UDP 프로토콜을 이용하여 저비용으로 통신할 수도 있다.
TCP 프로토콜은 호스트에서만 작동하고, 중간 라우터 노드들에서는 작동하지 않는다. 앞서 언급했듯이 TCP 프로토콜은 복잡한 처리를 요구하기 때문에 모든 중간 라우터 노드들에서까지 TCP 프로토콜을 작동하게 한다면 지금처럼 많은 데이터 전송을 처리할 수가 없기 때문이다.
TCP 프로토콜
TCP 프로토콜의 기능은 신뢰성 있는 데이터 전송(Reliable Data Transfer, RDT), 연결 제어(Connection Control), 흐름 제어(Flow Control), 혼잡 제어 (Congestion Control)가 있다. 만약 은행 서비스를 이용하는데 금액에 대한 데이터 전송이 잘 못되어 1억원을 보낸 것이 1만원을 보냈다고 처리되면 끔찍할 것이다. TCP 프로토콜의 신뢰성 있는 전송 기능이 있기 때문에 TCP 프로토콜 기반의 통신은 전송자가 보낸 데이터를 수신자가 그대로 전송받는다고 믿을 수 있다. TCP 프로토로 전송을 시작하는 것부터 각 기능을 제공하기 위한 자세한 방법을 알아보자.
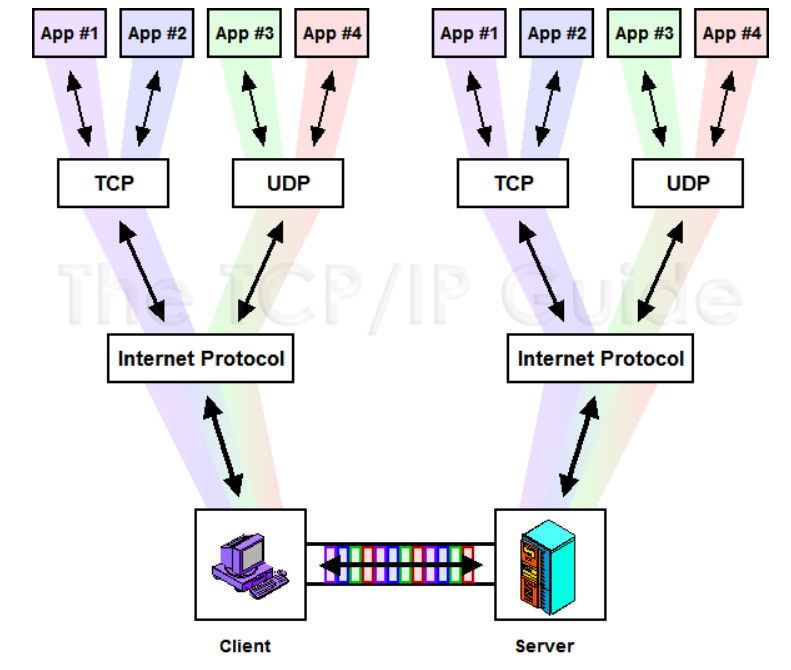
Multiplexing / Demultiplexing
응용 프로그램이 소켓을 통해 데이터를 전송하는 것부터 TCP 프로토콜이 시작된다. 한 컴퓨터에서 여러 개의 소켓과 프로세스가 존재할 수 있기 때문에 OS에서는 소켓과 프로세스를 식별하기 위해 포트(port) 번호를 따로 둔다. 한 서버에서 여러 소켓과의 연결을 유지하는 것을 생각해보면 왜 이러한 기능이 필요한지 알 수 있을것이다. 그러나 보통 컴퓨터에 연결된 통신 링크는 하나이기 때문에 하나의 링크를 통해 여러 소켓의 데이터를 주고받아야 한다. 이를 위해 OS에서는 전송하려는 데이터를 TCP/UDP 세그먼트로 만들 때 헤더를 추가하여 공통적으로 출발지 포트 번호와 목적지 포트 번호를 둔다. 이러한 작업을 Multiplexing 이라 하고, 목적지에 도착한 세그먼트는 헤더를 확인하여 Demultiplexing 된 뒤 대상 소켓에게 데이터를 전달한다. 편지를 보낼 때 주소뿐만 아니라 그 주소의 누구에게 보내는 것인지도 함께 명시하는 것을 생각하면 이해가 쉬울 것이다.
신뢰성 있는 통신
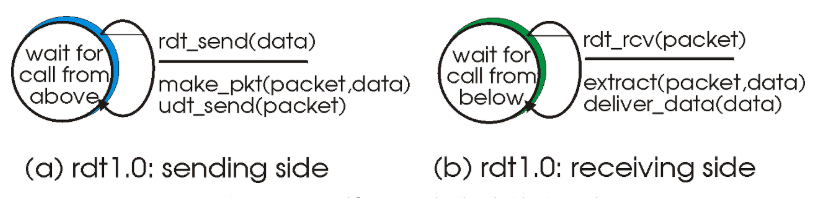
신뢰성 없는 통신을 기반으로 신뢰성 있는(오류 없는) 통신을 지원하기 위해 단계적으로 가정을 줄이고 상황을 일반화시켜나간다. 신뢰성 있는 통신을 한다는 것은 잘못된 데이터를 전송받지 않고, 데어터의 순서 또한 유지되는 통신을 보장한다는 뜻이다. 이 항목에서 설명하는 내용은 이곳을 요약하였다. 아래 그림은 신뢰성 있는 통신 서비스를 어떻게 제공하는지 보여주는 그림이다. 신뢰성 있는 데이터 전송 함수인 rdt_send 함수는 내부적으로 신뢰성 없는 채널을 이용하여 udt_send 함수를 이용하여 구현된다.

첫 시작인 rdt1.0 에서는 신뢰성 있는 채널을 통해 데이터 전송이 이뤄진다고 가정한다. 데이터 전송에 에러가 발생하지 않는다는 가정 하의 전송이기 떄문에 rdt_send 함수는 받은 데이터를 패킷으로 만들고 udt_send 함수로 패킷을 전송하기만 해도 신뢰성 있는 통신이 된다. 물론 수신자 측은 받은 패킷을 합쳐 데이터로 돌리면 된다.
rdt2.0에서는 비트 에러가 존재할 수 있는 상황까지 수용한다. 전화 통화에서 받아쓰기를 한다고 생각해보자. 아마 상대방이 한 문장씩 말할 때마다 잘들었다는 응답(syn) 혹은 다시 말해달라는 응답(Please repeat that)을 통해 받아쓰기를 잘 하고 있는지 확인할 수 있을 것이다. rdt2.0에서는 이 방식을 모티브로 삼아 작동하며, 이러한 응답을 통한 통신조절을 (ARQ(Automatic Repeat request)라고 한다.
rdt2.0에서는 여기에 두 가지 추가적인 기능이 요구된다. 첫 번째로 신뢰성 없는 채널을 통한 통신이 이뤄지기 때문에 비트 에러가 있는지 감지할 수 있어야 한다. 이 감지를 위한 방법으로는 checksum이라는 훌륭한 방법이 있다. 두 번째로 수신자로부터 피드백을 받을 수 있어야 한다. 송신자는 수신자의 어떠한 피드백 없이는 전송이 어떻게 이뤄졌는지 알 수 없다. 이 피드백을 위해 수신자는 송신자로부터 데이터를 성공적으로 받았을 때 ACK, 잘못 받았을 때 NAK을 보낸다. 아래 사진을 보면 수신자 측에서 패킷을 성공적으로 받았을 때 Ack, 잘못 받았을 때 Nak을 보낸다. 아래 사진을 보면 수신자 측에서 패킷을 성공적으로 받았을 때 패킷이 손상되었다면(corrupt) Nak 을 보내고, 패킷이 손상되지 않았다면 Ack(Not Corrupt) 를 봅내는 것을 확인 할 수 있다. 이런 식으로 송신 후 기다리기 때문에 rdt2.0은 stop-and-wait 프로토콜로 알려져 있다.
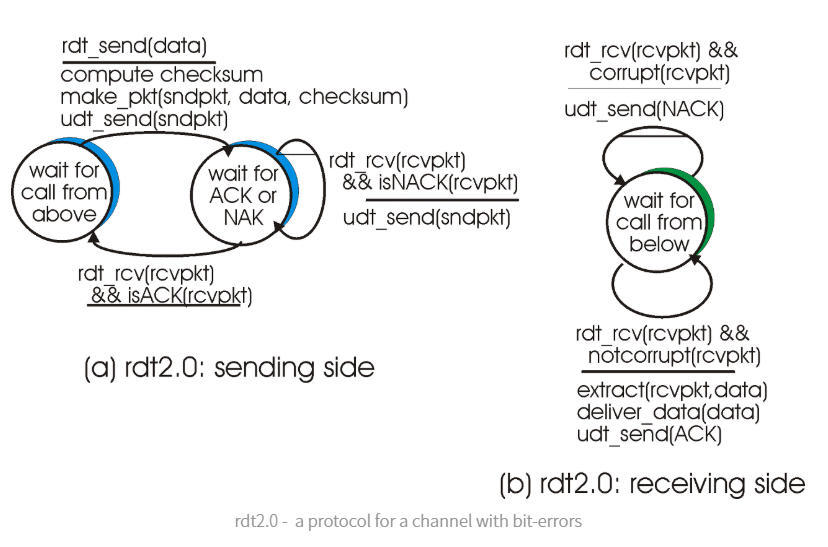
그러나 Ack와 Nak 응답도 에러가 발생할 수 있다. Ack도 Nak도 오지 않으면 송신자 측에서는 무한정 기다리게 된다. 송신 측에서는 에러가 났는지 알 수가 없다. 또한, 중복 송신을 하게 되면 중복수신을 하게 된다.
rdt2.1에서는 순서 번호(Sequence number)를 추가함으로써 중복 수신을 방지한다. 순서 번호만 확인하면 중복된 데이터를 받았는지 알 수 있으므로 중복 수신을 방지할 수 있다. stop-and-wait 프로토콜 상으로는 방금 전송한 패킷이 잘 전송되었는지만 알면 되기 때문에 순서 번호가 0 혹은 1만 있으면 된다. 아래 그림은 rdt2.1을 나타낸 그림이다. 0에 대한 패킷 전송 완료 후에는 1에 대한 패킷 전송을 하고, 그 후에는 다시 0에 대한 패킷을 전송한다. rdt2.0의 가정상 아직 패킷이 유실될 수 있는 상황은 아니기 떄문에 이 방법은 문제가 없다.

여기서 잘못된 수신에 대한 Nak 응답이 아닌 Ack을 이용한 방법이 가능하다. rdt2.2는 Nak을 사용하지 않는 방법이다. Ack에 순서 번호를 추가함으로써 잘못된 데이터를 받은 것을 다시 송신하게 할 수 있다.
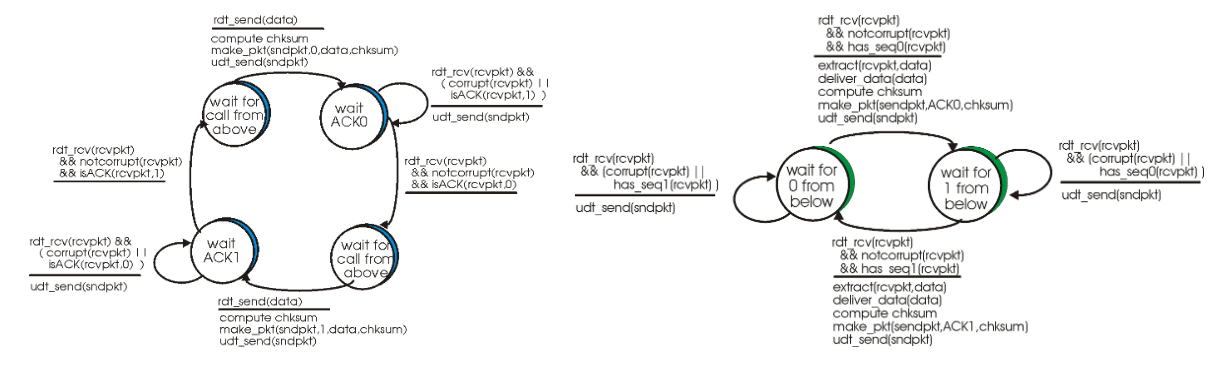
ㅇ이제는 심지어 패킷이 사라질 수도 있는 채널을 통해 통신한다고 가정하자. 이 경우엔 패킷 손실을 어떻게 감지할 지, 그리고 패킷 손실이 발생하면 어떻게 해야 할 지 생각해봐야 한다. 패킷 손실이 됐을 때 대응방법은 이미 rdt2.2까지의 고민을 통해 알 수 있다. 다시 보내는 것, 쉽고 간단한 방법으로 해결된다. rdt3.0에서는 송신자가 Ack을 받는 것에 대한 타임 아웃 타이머를 둬서 이를 해결한다. 시간 내에 데이터를 성공적으로 수신했다는 응답을 받지 못하면 데이터를 다시 보내는 것이다. 중복된 데이터 수신에 대해서는 이미 rdt2.2 상에서 처리된다.
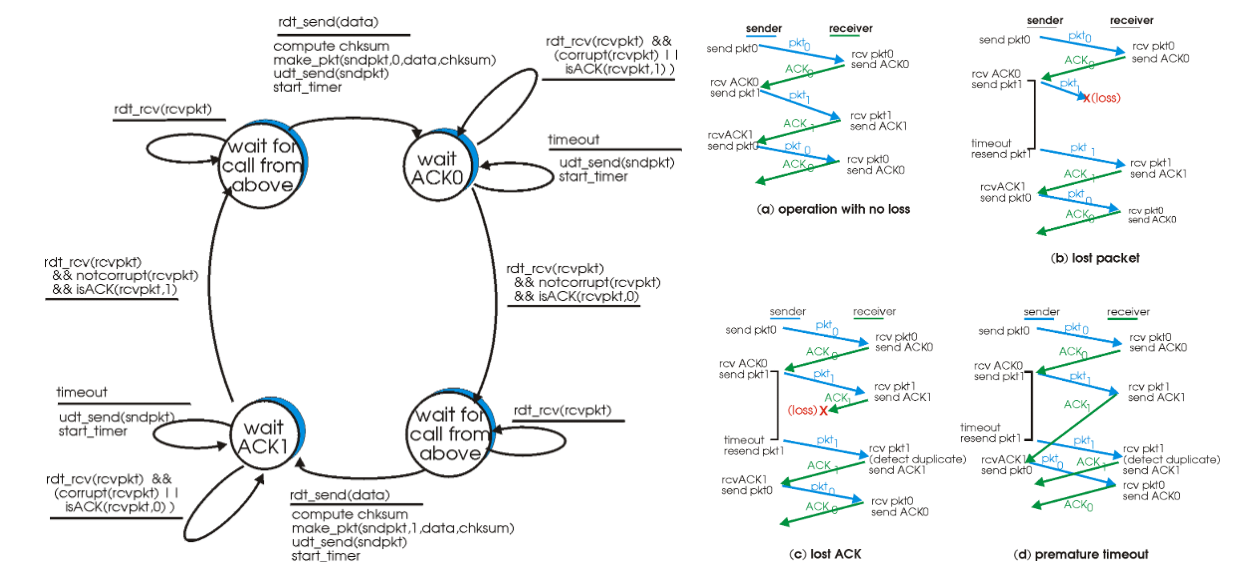
rdt3.0까지 발전시켜나감으로써 이제 신뢰성 있는 통신을 할 수 있게 됐다. 하지만 이 방법은 한 번에 한 패킷씩 밖에 보내지 못하기 때문에 성능상으로 만족스럽지 못하다. 매우 먼 거리에 패킷을 보내려 한다면 패킷이 왔다 갔다(Round trip)하는 것을 기다리는 시간 때문에 전송 속도가 매우 떨어질 것이다. 이제는 여러 패킷을 보낼 방법을 고민해야 한다. Ack 을 받기 전에 다수의 패킷을 전송하는 방법을 통틀어 파이프라인 프로토콜이라고 하며, 세부적으로 GBN(Go-Back-N), SR(Selective Repeat) 프로토콜이 있다.
Go-Back-N 프로토콜은 수신자 측에서 지금까지 성공적으로 받은 패킷 순서 번호에 대한 Ack을 전송하며, 순서에 맞지 않는 패킷은 성공적으로 수신한 것으로 간주하지 않는다. 따라서, 송신자는 Ack를 받지 못한 가장 오래된 패킷부터 모두 재전송하게 된다. Selective Repeat 프로토콜은 잘못된 순서의 패킷을 받았더라도 버퍼에 저장해둔다. 중간에 수신 실패한 패킷만 다시 전송하게끔 수신자 측은 개별적으로 Ack를 전송하며, 송신자 역시 패킷마다 타임 아웃 타이머를 가진다. Selective Repeat 프로토콜상으로는 상위 계층에게 현재 성공적으로 수신한 패킷까지만 제공함으로써 해당 패킷까지 신뢰성 있게 통신되었음을 보장한다. 아래 사진은 GBN 프로토콜과 SR 프로토콜을 요약한 사진이다.
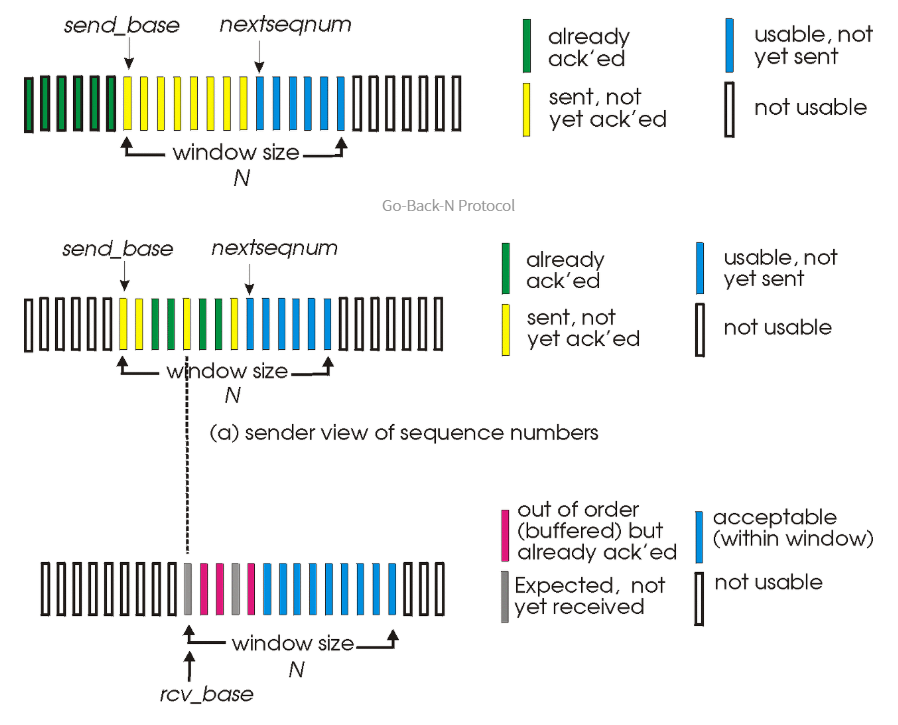
이로써 신뢰성 없는 채널을 통한 신뢰성 있는 통신을 구현하는 방법에 대해 알아보았다. 실제 TCP에서는 Go-Back-N 프로토콜과 Selective Repeat 프로토콜을 하이브리드하여 사용된다고 한다.
적절한 타임 아웃 시간 예측
여기서 의문이 생길 수 있는 부분은 타임 아웃 시간은 어떻게 결정할까?
타임 아웃 시간을 너무 짧은 시간으로 두면 재전송 요청을 많이하게 되고, 너무 긴 시간으로 두면 기다리는 시간이 길어진다. 적절한 타임 아웃 시간을 설정하기 위한 방법으로 그떄 그때 확인 된 RTT(Round Trip Time, 패킷이 갔다 오는데 걸린 시간) 인 SampleRtt를 이용하여 다음 RTT인 EstimateRTT를 예측한다. 원리는 이전까지의 RTT와 다음 RTT는 비슷할 것이고, 변화가 생기면 소폭 반영하는 것이다. 식을 살펴보자
nextEstimatedRTT = (1-a)*previousEstimatedRTT+a*sampleRTT
적절한 a, 예를들면 0.125 정도를 설정하면 과거의 데이터에 더 비중을 둬서 변화를 수용하게 된다.
연결 제어
TCP 프로토콜은 연결 지향 프로토콜이고, 신뢰성 있는 통신을 제공하기 위하여 순서 번호를 사용한다고 하였다. TCP 프로토콜에서 통신이 이뤄지기 위해서는 먼저 서로 연결이 되어야 하고, 서로 임의의 시작 순서 번호를 알려줘야 한다. 그 과정을 3-way handshaking 이라고 한다. 다음 박스의 내용은 연결 시작을 위한 3-way handshaking 과정을 보여준다.
다음 박스의 내용은 연결 시작을 위한 3-way handshaking 과정을 보여준다.
person1 --> person2 SYNchronize with my Initial Sequence Number of X
person1 <-- person2 I received your syn, I ACKnowledge that i am ready for [X+1]
person1 <-- person2 SYNchronize with my Initial Sequence Number of Y
person1 --> person2 I received your syn, I ACKnowledge that i am ready for [Y+1]
TCP 프로토콜에서는 연결하자는 뜻으로 SYN 패킷을 보낸다. SYN은 SyNchronize의 약자로 person1은 SYN 패킷과 함께 초기 순서 번호 (Initial Sequence Number, ISN)을 person2에게 보낸다. person2 는 Person1의 초기 순서 번호가 X 인것을 알게 되고, Person1에게 SYN, ACK 가 합쳐진 패킷을 보내면서 자신의 초기 순서 번호가 Y임을 알려준다. 마지막으로 Person1 은 Person2로부터 초기 순서 번호를 잘 받았다는 의미로 ACK을 보낸다. 이 과정을 통해 두 호스트는 신뢰성 있는 통신을 할 수 있는 준비를 마치게 된다.

실제로는 3-way handshaking 과정에서 초기 순서 번호 외에도 수신 기본 윈도우 크기(rwnd), 여러 가지 추가적인 옵션 등을 교환하게 된다. 왜 2-way handshaking으로는 안 되는 걸까? 아래 사진은 2-way handshaking의 실패 시나리오다. 호스트 A가 호스트 B에게 연결 요청을 한 것이 딜레이가 많이 되어서 다시 연결 요청을 하는 상황이 발생할 수 있다. 그 경우 호스트 B는 과거의 연결 요청에 대한 순서 번호로 응답을 하게 되고, 호스트 A는 잘못된 순서 번호의 패킷이 왔기 때문에 그 패킷을 버리게 된다. 따라서 성공적으로 통신을 할 수 없게 된다.
