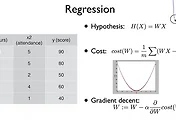
이론시간 에 배웠던 Logistic Regression 을 한번더 살펴보면 다음과 같습니다!

아직 X의 크기가 정해지지 않았기 때문에 len을 입력합니다.
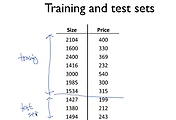
data 는 다음과 같습니다.
이 때 X0를 모두 1로 해준 이유는 b를 제거하기 위해서입니다.

코드는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | import tensorflow as tf import numpy as np xy = np.loadtxt('train.txt',unpack=True, dtype = 'float32') x_data = xy[0:-1] y_data = xy[-1]; X = tf.placeholder(tf.float32) Y = tf.placeholder(tf.float32) W = tf.Variable(tf.random_uniform([1,len(x_data)],-1.0,1.0)) #Our hypothesis h = tf.matmul(W, X) hypothesis = tf.div(1., 1.+tf.exp(-h)) #cost function cost = -tf.reduce_mean(Y*tf.log(hypothesis)) - (1-Y)*tf.log(1-hypothesis) #Minimize a = tf.Variable(0.1) #Learning rate, alpha optimizer = tf.train.GradientDescentOptimizer(a) train = optimizer.minimize(cost) #Before starting, initialize the variables. We will 'run' this first. init = tf.initialize_all_variables() #Launch the graph. sess = tf.Session() sess.run(init) #Fit the line. for step in xrange(2001): sess.run(train, feed_dict = {X:x_data, Y:y_data}) if step % 20 ==0: print step, sess.run(cost, feed_dict={X:x_data, Y:y_data}), sess.run(W) print '---------------------------------------' #study hour attendance print sess.run(hypothesis, feed_dict = {X:[[1],[2],[2]]})>0.5 print sess.run(hypothesis, feed_dict={X:[[1],[5],[5]]})>0.5 print sess.run(hypothesis, feed_dict = {X:[[1, 1], [4, 3] ,[3, 5]]})>0.5 | cs |
이 트레이닝 data 를 토대로 Ask to ML 을 해보도록 하겠습니다.
x1 = 5, x2 = 3 인사람이 통과할 수 있을까요?
1 2 3 4 5 6 7 | print '---------------------------------------' #study hour attendance print sess.run(hypothesis, feed_dict = {X:[[1],[2],[2]]})>0.5 print sess.run(hypothesis, feed_dict={X:[[1],[5],[5]]})>0.5 print sess.run(hypothesis, feed_dict = {X:[[1,1][4,3],[3,5]]})>0.5 | cs |
다음과 같이 한명을 물어볼 수도, 벡터를 통해서 여러명을 물어볼 수도 있습니다!

이렇게 결과를 알 수 있습니다!
'머신러닝' 카테고리의 다른 글
| [강의]시즌1 딥러닝의기본 - Training/Testing 데이타 셋 (0) | 2017.02.17 |
|---|---|
| [강의]시즌1 딥러닝의기본 - Softmax Regression에 대하여 알아보자! (0) | 2017.02.17 |
| [강의]시즌1 딥러닝의기본 - Logistic (regression) classification에 대해 알아보자 (0) | 2017.02.15 |
| [실습] 모두의딥러닝 - multi-variable linear regression을 TensorFlow에서 구현해버리기 (0) | 2017.02.15 |
| [실습] 모두의딥러닝 - linear regression의 cost 최소화의 Tensorflow를 구현해보자! (0) | 2017.02.15 |